
Umetna inteligenca in strojno učenje sta danes zelo modni besedi. Obe tehnologiji se predstavlja bodisi kot rešitev za različne težave današnjega sveta, bodisi kot končni korak do apokalipse. Ne glede na to pa je dejstvo, da poteka široka razprava o tem, kaj ti tehnologiji pravzaprav sta in kaj v resnici lahko ali bosta zmogli v prihodnosti.
Besedilo “Kaj je umetna inteligenca in zakaj je pomembna?” je del informativnega gradiva (str. 28-36) za udeležence/ke globalnega občanskega dialoga Mi, internet, ki je v Sloveniji potekal oktobra 2020. Gradivo je v slovenski jezik prevedel mag. Simon Delakorda, Inštitut za elektronsko participacijo (INePA).
Kazalo
Opredelitev umetne inteligence
Upravljanje umetne inteligence
Opredelitev umetne inteligence
Mnogi so poskušali opredeliti umetno inteligenco (UI), vendar še nismo prišli do definicije, s katero bi se vsi strinjali. Pogosto so opredelitve zelo nejasne, zato je težko razumeti, za kaj dejansko gre pri umetni inteligenci. Na primer, v pogosto citirani splošni definiciji je UI opisana kot “tehnika, ki omogoča, da računalniški sistemi posnemajo katero koli vrsto inteligence“. Poenostavljeno to pomeni, da je stroj sposoben reševati določene probleme.
Čeprav obstajajo številne fantazijske in znanstveno izmišljene ideje o zmožnosti umetne inteligence, lahko danes sistemi UI rešujejo le zelo dobro opredeljene probleme. To področje se pogosto nanaša na ozko umetno inteligenco. V primerjavi z njo se splošna umetna inteligenca nanaša na sisteme, ki lahko izvajajo katero koli inteligentno nalogo, ki bi jo lahko opravil človek. Ker je splošna umetna inteligenca še vedno bolj znanstvena fantastika kot resničnost in zelo hipotetična, se bomo v nadaljevanju osredotočili na ozko umetno inteligenco, ki že obstaja v praksi.
Zakaj je tako težko oblikovati splošno sprejeto definicijo umetne inteligence?
Razlog je v tem, da trenutno nimamo ustrezno opredeljene niti človeške inteligence. Da ne govorimo o inteligenci živali. Pomislimo samo na vprašanje, kaj se nam zdi resnično inteligentno? Poleg vprašanja same inteligence obstajajo tudi nesoglasja glede tega, kaj vključuje umetna inteligenca. Medtem, ko nekateri pojmujejo umetno inteligenco kot tehnični postopek, jo drugi opredeljujejo kot kombinacijo programske, strojne in podatkovne opreme. V vsakem primeru pa umetna inteligenca vključuje različna orodja in metode.
Aktualna področja uporabe umetne inteligence
Na kratko si oglejmo nekaj področij uporabe umetne inteligence, ki jih morda že poznate.
- Prepoznavanje govora: Siri podjetja Apple in Alexa podjetja Amazon sta primera inteligentnih sistemov, ki uporabljata umetno inteligenco za prepoznavanje vnešenega govora
- Osebne prilagoditve: številne spletne storitve kot so platforme družbenih medijev ali Netflix in Amazon, uporabljajo umetno inteligenco za uporabnikom prilagojeno prikazovanje vsebin na spletnih straneh. Spletne storitve se učijo na podlagi vašega in obnašanja drugih uporabnikov. Na primer: če ste gledali samo kriminalke ali kupovali predvsem znanstvenofantastične romane, vam bodo prilagojeni prikazi priporočali vsebine, ki najverjetneje ustrezajo vašemu zanimanju.
- Filtriranje e-pošte: e-poštne storitve uporabljajo umetno inteligenco, ki ločuje med neželenimi in zaželenimi sporočili. Nekateri ponudniki storitev filtrirajo dohodna e-poštna sporočila kot so npr. oglasi v ločene e-poštne mape.
- Pregled kandidatov: nekatera podjetja, ki prejemajo veliko prijav za odprta delovna mesta, uporabljajo filtriranje primernih kandidatov od manj primernih. Umetna inteligenca tako pomaga pri vnaprejšnji selekciji prejetih prijav.
- Klinična diagnoza: v medicini se umetna inteligenca vse bolj uporablja v pomoč zdravnikom pri postavljanju diagnoz.
Področij uporabe umetne inteligence je seveda veliko več. Nekatere uporabe imajo zelo pozitiven vpliv na posameznike in družbo kot celoto ter prinašajo velike priložnosti. V drugih primerih uporabe pa se kaže, da umetna inteligenca diskriminira in prikrajša nekatere skupine ljudi. Sedaj si bomo pogledali, zakaj aplikacije umetne inteligence odpirajo vprašanja odgovornosti, pristranskosti, preglednosti, kakovosti podatkov ali drugih etičnih dilem. Začeli bomo s strojnim učenjem (SU), ki je podlaga za razcvet umetne inteligence v zadnjih letih.
Kaj je strojno učenje?
Strojno učenje je kot posebno vrsto umetne inteligence veliko lažje opredeliti. Strojno učenje (SU) se nanaša na algoritme in tehnike, ki imajo sposobnost samostojnega učenja pri uporabi podatkov, opazovanjih in komunikaciji s svetom okoli njih.
Algoritmi so navodila za reševanje naloge. Programerji pišejo algoritme, ki sporočajo računalniku, kako se lotiti problema. Ti algoritmi pravzaprav gradijo digitalni svet. Algoritmi na podlagi pravil in navodil organizirajo podatke in nam omogočajo uporabo storitev in informacij.
Algoritmi strojnega učenja so posebna vrsta algoritmov. Namesto, da bi jih programirali človeški programerji, se algoritmi SU učijo sami s pomočjo statističnega pristopa. To pomeni, da lahko algoritmi strojnega učenja sami prilagajajo začetne parametre na podlagi pridobljenih podatkov in razvijejo lastna pravila z izdelavo statističnega prikaza okolja, ki jim je dano. Ti algoritmi ne vsebujejo podrobnih pravil, temveč navodila, kako se “učiti” in kako preseči posamezne parametre. Ta proces pogosto imenujemo tudi učenje algoritma strojnega učenja.
Algoritmi strojnega učenja so zaradi statističnega pristopa še posebej uspešni pri prepoznavanju vzorcev v zelo velikih naborih podatkov. Ta sposobnost omogoča uporabo računalnikov za naloge, ki bi bile drugače preveč zapletene ali celo nemogoče, če bi jih želeli narediti ročno. V zadnjem desetletju je napredek v strojnem učenju privedel do velikih izboljšav na področjih, kjer se problemi rešujejo z iskanjem vzorcev v zelo velikih količinah podatkov. Na primer pri prevajanju, prepoznavanju slik, napovedovanju borznih trendov in v prej omenjenih primerih uporabe.
Čeprav je vse strojno učenje mogoče šteti za umetno inteligenco, obratno temu ni tako. Običajni žepni računalnik za šolo je na primer veliko hitrejši pri izračunu določenih enačb kot povprečen človek. Zato se lahko šteje kot primer uporabe umetne inteligence. Vendar pa se žepni računalnik opira na točno določena pravila, ki so jih postavili ljudje in se sam ne more učiti (žepni računalnik zato ni sistem strojnega učenja).
Proces strojnega učenja
Kako torej deluje strojno učenje? In kaj dejansko pomeni učenje algoritma? Ne skrbite, to ne bo tehnična razlaga. Na spodnji sliki lahko vidite poenostavljen postopek strojnega učenja, ki se začne z zbiranjem podatkov in konča z uporabo naučenega algoritma v določenem kontekstu. Čeprav obstaja več metod strojnega učenja, bomo uporabili vzorčen primer. Na splošno lahko postopek strojnega učenja razdelimo na dve stopnji:
1. Najprej je treba naučiti algoritem strojnega učenja. Rezultat prve stopnje je model strojnega učenja.
2. Na drugi stopnji se model aplicira na želeno področje uporabe. Rezultat tega koraka je na primer napoved verjetnosti, da bo bolnik imel rakast tumor ali verjetnost, da bo kandidat za službo ustrezal podjetju.
Spodnja slika prikazuje stopnji učenja in uporabe.
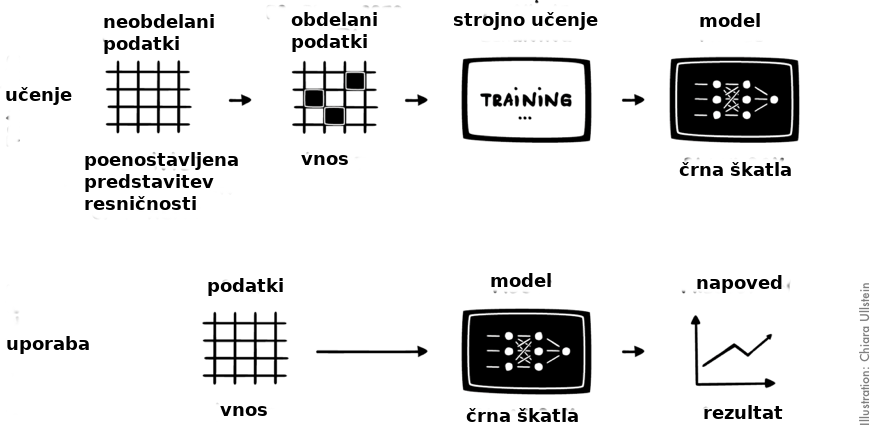
V prvem koraku učenja se zbirajo podatki. Podatke lahko zberejo ljudje z različnimi metodami. Na primer z anketiranjem, fotografiranjem ali pa jih samodejno zberejo in ustvarijo računalniki.
V drugem koraku se zbrani podatki obdelajo (npr. ustrezni podatki se ločijo od nepomembnih). Ta korak se pogosto imenuje tudi predhodna obdelava. Predhodna obdelava lahko pomeni tudi obogatitev podatkov, da postanejo izčiščeni in bolj natančni. Rezultat tega koraka je urejen nabor obdelanih podatkov.
Obdelani podatki se nato uporabijo kot vhodni podatki za proces učenja. Tekom procesa se učni algoritem “uči” iz vnesenih obdelanih podatkov. Učenje zajema statistično prepoznavanje vzorcev v vhodnih podatkih in ustvarjanje novega sklopa pravil na podlagi najdenih vzorcev.
Dejansko se tako ustvari nov algoritem. Novi algoritem je rezultat učnega procesa, ki se imenuje model strojnega učenja. Model strojnega učenja pogosto imenujemo črna škatla, ker je, odvisno od izbranega učnega algoritma, težko razumeti dogajanje znotraj algoritma.
Ko je model usposobljen, ga je mogoče uporabiti. V fazi uporabe se v model vnesejo novi podatki, na podlagi katerih strojno učenje ustvari rezultat v obliki napovedi, prevoda, najbolj ustrezne izbire itd.
Postopek strojnega učenja lahko vodi ena oseba ali pa velika ekipa ljudi. Odvisno od projekta, se lahko faza uporabe zaključi v zelo kratkem času ali pa traja zelo dolgo. Strojno učenje se uporablja tako v akademskih raziskavah kot v industriji. Obstajajo različni priročniki, ki pomagajo ljudem, da sami vzpostavijo in uporabijo enostaven model strojnega učenja.
Nekateri izzivi strojnega učenja
Aplikacije umetne inteligence lahko najdemo povsod. Ljudem so lahko v veliko oporo in pomagajo lajšati življenje. Odločitve, sprejete s pomočjo umetne inteligence (ali predlogi za odločitve), lahko močno vplivajo na življenja ljudi.
Strojno učenje je lahko še posebej zapleteno in je posledično vir številnih napak. Na primer, med zbiranjem podatkov se lahko zgodi napačno ali pristransko zbiranje ter napačno dokumentiranje. Tekom obdelave podatkov lahko ustrezne vire nepravilno filtriramo. Med učenjem algoritma se lahko zgodijo napake pri programiranju in pri izbiri navodil. Pri uporabi naučenega modela se lahko zgodi, da novi podatki ne ustrezajo vzorcu, ki je bil uporabljen pri učenju. Na koncu se lahko tudi zgodi, da si rezultate strojnega učenja napačno razlagamo.
Z družbenega vidika predstavlja veliko nevarnost nekritičen odnos do podatkov, ki se uporabljajo kot podlaga za strojno učenje. Za popoln nabor podatkov bi bilo potrebno zbrati vse možne dejavnike, ki sestavljajo realnost ali vplivajo nanjo. Kar pa pravzaprav nikoli ni mogoče. Podatki so vedno le poenostavljena predstavitev stanja z upoštevanjem omejenega števila dejavnikov. To še posebej velja za podatke o družbi.
Podatki, ki naj bi predstavljali stanje v družbi, vedno vsebujejo tudi obstoječe probleme in neenakosti našega sveta. Teh struktur (vzorcev) se nauči tudi algoritem strojnega učenja in jih nato vključuje v svoje napovedi. To lahko privede do pristranskih napovedi v škodo tistih družbenih skupin, ki so na primer manj zastopane v naboru podatkov. Čeprav bi moral nabor podatkov prikazoval reprezentativni vzorec družbe.
Preprosto povedano: smeti noter, smeti ven.
V primeru pristranskosti strojnega učenja to seveda pomeni, da bodo pristranski podatki povzročili tudi pristranske napovedi. In ker je, kot omenjeno zgoraj, glavna prednost strojnega učenje iskanje vzorcev v podatkih in izpeljava sklepov, imajo vhodni podatki za strojno učenje ključen pomen. Dejansko je kakovost rezultatov strojnega učenja zelo odvisna od kakovosti in količine podatkov.
Da bo strojno učenje zagotavljajo dobre rezultate, je pomembno, da so nabori podatkov dovolj veliki. Običajna velikost podatkov presega količino podatkov, ki bi jih ljudje lahko pravilno analizirali. Vendar pa ni vedno lahko zbrati ali najti kakovostne podatke. Takšen primer so redki pojavi ali družbene okoliščine, katere je težko opredeliti v številkah. Kadar nabori podatkov niso dovolj kakovostni ali pa so premajhni, so lahko rezultati strojnega učenja zlahka nenatančni in slabe kakovosti.
Zanimivo je, da napredek na področju rabe umetne inteligence in strojnega učenja ni toliko posledica zelo inovativnih algoritmov, kot je dejansko posledica dostopnosti velikih količin podatkov.
Kdo je odgovoren?
Pri uporabi zapletenih modelov strojnega učenja težko razumemo (spomnimo se samo na črno škatlo), kako je sistem prišel do določenega rezultata (napovedi). S tem je povezano pomembno vprašanje: Kdo je odgovoren za rezultate uporabe umetne inteligence v primeru, da pride do nesreče, napačne diagnoze ali diskriminacije posameznika?
Preglednost strojnega učenja lahko pomaga zagotoviti odgovornost (npr. kako je strojno naučena zdravstvena aplikacija prišla do določene napovedi bolezni ali zakaj je samovozeči avtomobil zavil levo in ne desno? Razumevanje, kako modeli strojnega učenja pridejo do rezultatov, je pomembno za opredelitev odgovornosti, zlasti v primeru napačnih odločitev ali nesreč.
Zato bi bilo morda smiselno izbrati modele strojnega učenja, ki so manj zapleteni, čeprav dajejo manj natančne rezultate. Poleg zapletenosti strojnega učenja, se izziv preglednosti pojavlja tudi pri državnih tajnostih ali poslovnih skrivnosti podjetij. Številni procesi strojnega učenja se uporabljajo tajno in jih javnost ne more nadzorovati.
Poleg tega so algoritmi strojnega učenja pogosto usposobljeni le za reševanje zelo specifičnih nalog. Včasih lahko učenje algoritma traja več dni, s čimer porabimo veliko električne energije in naredimo velik okoljski odtis. Običajni osebni računalnik ni dovolj zmogljiv za učenje zapletenih algoritmov, ker je potrebno veliko računske moči.
Zaključimo lahko, da niso vsi konteksti, zlasti pa ne vse družbene situacije primerne za uporabo rešitev umetne inteligence. Vhodni podatki niso nevtralni in niso popolni. V poenostavljeni in nepopolni obliki zrcalijo družbene strukture, vključno s pristranskostmi in neenakostmi. Algoritem strojnega učenja se uči iz teh vzorcev in na njihovi podlagi ustvarja rezultate. Modeli strojnega učenja so dobri le toliko, kolikor so dobri vhodni podatki in kako natančni so posamezniki, ki načrtujejo, programirajo in uporabljajo strojno učenje ter skrbijo za njegov ustrezen razvoj in uporabo.
Upravljanje umetne inteligence
Čeprav zgoraj predstavljen seznam izzivov še zdaleč ni celosten, pa izpostavljena vprašanja opozarjajo na potrebo po upravljanju in regulaciji umetne inteligence, s katero bi se izognili negativnim učinkom. Do sedaj je bilo na nacionalnih ravneh veliko razprav o tem, kako upravljati umetno inteligenco. Številne države so objavile nacionalne strategije za umetno inteligenco in skoraj vsa velika podjetja in nevladne organizacije so objavile članke o svojem dojemanju dobrih praks umetne inteligence.
Mnogi od teh dokumentov vsebujejo veliko dragocenih idej in predlogov. Čeprav je etičnim vidikom umetne inteligence namenjena širša pozornost, ostaja izvajanje teh načel še vedno veliko vprašanje. Razmišljanja o upravljanju umetne inteligence na globalni ravni so še vedno na začetku in razprave, ki vključujejo vse zainteresirane strani, vključno z industrijo, vladami in uporabniki, so nujne.
V nadaljevanju vam predstavljamo sklop priporočil o etiki umetne inteligence, katera je maja 2020 pripravila strokovna skupina pri Organizaciji Združenih narodov za izobraževanje, znanost in kulturo (UNESCO). Skupina je oblikovala naslednjih enajst političnih predlogov, ki se nanašajo na pet ciljev in so namenjeni kot politična priporočila državam članicam Združenih narodov (ZN).
CILJ I: Etično skrbništvo
1. Spodbujanje raznolikosti in vključenosti
To priporočilo se nanaša na aktivno sodelovanje vseh držav članic ZN pri preprečevanju kulturnih in socialnih stereotipov, neenakostih ter spoštovanju lokalnih in mednarodnih kulturnih razlik in norm v delovanju sistemov umetne inteligence in njihovih podatkih. Prav tako izpostavlja odpravljanje vrzeli v razvoju sistemov umetne inteligence in poudarja zagovarjanje etike umetne inteligence na vseh ustreznih forumih.
CILJ II: Ocena učinka
2. Naslavljanje sprememb na trgu dela
Za ustrezno naslavljanje sprememb na trgu dela bi morale države članice zagotoviti primerne izobraževalne programe za vse generacije. To vključuje ukrepe za izpopolnjevanje in preusposabljanje, pa tudi preučitev izobraževalnih programov na splošno. Za napovedovanje prihodnjih trendov bi morali raziskovalci analizirati vpliv umetne inteligence na lokalne trge dela. Korporacije, nevladne organizacije in druge zainteresirane strani bi si morale prizadevati za zaščito zaposlenih, na katere bodo najverjetneje vplivale spremembe na trgu dela zaradi umetne inteligence. Nenazadnje bi morale javne politike obravnavati zlasti manj zastopane skupine prebivalcev s ciljem omogočiti njihovo vključenost v digitalno gospodarstvo, ki temelji na umetni inteligenci.
3. Naslavljanje socialnih in ekonomskih vplivov umetne inteligence
Da bi preprečile neenakosti, bi morale države članice onemogočiti morebitne monopole, povezane z umetno inteligenco (npr. raziskave, tehnologije, podatki, trg). Izobraževanje ljudi o umetni inteligenci bi moralo prispevati k boljšemu dostopu do digitalnih tehnologij in zmanjšati digitalni razkorak. Poleg tega je potrebno uvesti sisteme ocenjevanja in spremljanja aplikacij umetne inteligence, etične politike umetne inteligence ali certificiranje sistemov umetne inteligence. Države članice bi morale spodbujati zasebne subjekte, da začnejo izvajati ukrepe za oceno učinka, revizijo, spremljanje in etično skladnost, kot je izmenjava z različnimi zainteresiranimi stranmi pri upravljanju umetne inteligence ali uvedba pooblaščenca za etiko umetne inteligence. Poleg tega bi morale strategije upravljanja podatkov zagotavljati ustrezno kakovost vhodnih podatkov.
4. Vpliv na kulturo in okolje
Sisteme umetne inteligence je treba uporabiti pri ohranjanju, bogatenju in razumevanju kulturne dediščine. Treba je preučiti, kako lahko sistemi umetne inteligence, kot sta glasovna pomoč ali avtomatizirano prevajanje, vplivajo na človeški jezik. Potrebno je raziskati, kakšni so dolgoročni učinki interakcije človeka s sistemi umetne inteligence. Spodbujati je treba izobraževanje o umetni inteligenci za zaposlene v ustvarjalnih poklicih ter vrednotenje in ozaveščanje o orodjih za umetno inteligenco. Poleg tega je treba oceniti in zmanjšati vpliv sistemov umetne inteligence na okolje.
CILJ III: Vzpostavitev zmogljivosti za etiko umetne inteligence
5. Spodbujanje izobraževanja in ozaveščanja o etiki umetne inteligence
Etiko umetne inteligence je treba vključiti v učne načrte šol in univerz, pri čemer je treba spodbujati sodelovanje med tehnološkim in družbenim področjem. Poleg tega bi morale temeljne spretnosti za izobraževanje o umetni inteligenci zagotavljati usposobljenost za kodiranje, osnovno pismenost in računanje. Spodbujati je treba programe za splošno ozaveščanje o umetni inteligenci ter dostop do znanja o izzivih in priložnostih. Poleg tega je treba raziskati, kako se lahko umetna inteligenca uporablja pri poučevanju. K sodelovanju je treba zlasti spodbujati invalide, ljudi različnih ras in kultur ter ženske. Najboljše prakse je treba spremljati in deliti z drugimi državami članicami.
6. Spodbujanje raziskav o etiki umetne inteligence
Države članice bi morale vlagati v raziskave o etiki umetne inteligence ali spodbujati naložbe zasebnega sektorja. Zagotoviti je treba usposabljanje raziskovalne etike za raziskovalce umetne inteligence in vključitev etičnih vidikov v zasnovo njihovih raziskav in končnega izdelka (vključno z analizo, označevanjem in kakovostjo podatkovnih nizov ter obsegom rezultatov). Države članice in industrija bi morale podpirati znanstvenoraziskovalno skupnost tako, da olajšajo dostop do podatkov. Spodbujati je treba tudi raznolikost spolov v akademskih raziskavah in industriji umetne inteligence.
CILJ IV: Razvoj in mednarodno sodelovanje
7. Spodbujanje etične uporabe umetne inteligence in razvoj
Države članice bi morale spodbujati etično uporabo umetne inteligence. Skupaj z mednarodnimi institucijami bi si morali prizadevati za vzpostavitve platform, ki omogočajo mednarodno sodelovanje pri razvoju umetne inteligence (infrastruktura, financiranje, podatki, znanje s področja, strokovno znanje, delavnice). Poleg tega je treba spodbujati mreže in raziskovalne centre za mednarodno sodelovanje na področju raziskav umetne inteligence.
8. Spodbujanje mednarodnega sodelovanja na področju etike umetne inteligence
Države članice bi morale raziskovati etiko umetne inteligence v okviru raziskovalnih ustanov in mednarodnih organizacij. Vsi subjekti bi morali zagotoviti enako in pošteno uporabo podatkov in algoritmov. Spodbujati je treba mednarodno sodelovanje za premostitev geografskih razlik ali posebnosti.
CILJ V: Upravljanje etike umetne inteligence
9. Vzpostavitev mehanizmov upravljanja za etiko umetne inteligence
Mehanizmi upravljanja umetne inteligence bi morali biti vključujoči (omogočati sodelovanje različnih ljudi vseh starostnih skupin), pregledni (dovoliti nadzor, preverjanje dejstev s strani medijev, zunanje revizije, nadzorne preglede), multidisciplinarni (celostno naslavljati probleme) in večstranski (temelječi na mednarodnih sporazumih). Treba je razviti digitalni ekosistem za etično umetno inteligenco, ki vključuje infrastrukturo, digitalne tehnologije in možnosti izmenjave ter dostop do znanja. Poleg tega je treba razviti in uporabljati smernice umetne inteligence v skladu z etičnimi načeli. Sčasoma bi se lahko razvil in izvajal mednarodni pravni okvir za pospeševanje mednarodnega sodelovanja med državami in drugimi zainteresiranimi stranmi.
10. Zagotavljanje zanesljivosti sistemov umetne inteligence
Ukrepe za spremljanje življenjskega cikla sistema umetne inteligence (podatki, algoritmi, akterji) bi morale izvajati države članice in zasebni subjekti. Poleg tega bi bilo treba opredeliti jasne zahteve glede preglednosti in razumljivosti sistemov umetne inteligence glede na področja uporabe, ciljne skupine in izvedljivost. Zato bi morale države članice z dodatnimi sredstvi spodbujati aktivnosti za večjo preglednost in boljše razumevanje umetne inteligence. Poleg tega bi bilo treba razmisliti o razvoju mednarodnih standardov za preglednost, ki bodo omogočali objektivno oceno in ugotavljanje skladnosti sistemov.
11. Zagotavljanje odgovornosti, obveznosti in zasebnosti
Pregledati in prilagoditi je potrebno okvire upravljanja sistemov umetne inteligence za doseganje odgovornosti za vsebino in rezultate v celotnem življenjskem ciklu sistema. Pomemben cilj je zagotoviti odgovornost ali obveznost za odločitve umetne inteligence, pri čemer morajo biti odgovorne za odločitve fizične ali pravne osebe in ne sistemi. V ta namen je treba sprejeti nove politike in zakone. Treba je odpravljati in kaznovati škodo, ki jo povzročajo sistemi umetne inteligence. Poleg tega je treba zagotoviti temeljno pravico do zasebnosti z ustreznimi ukrepi, posamezniki pa bi morali biti sposobni izkoristiti koncept “pravica do pozabe”, ki vključuje možnost nadzora nad uporabo zasebnih podatkov in možnost njihovega brisanja. Osebno določljivi podatki bi morali biti visoki varovani. Nenazadnje, potrebno je sprejeti okvir za nadzor in visoke standarde zbiranja in uporabe podatkov.
In vi?
Imate namen uporabljati umetno inteligenco in strojno učenje? Kateri so vaši glavni upi in strahovi v zvezi s to tehnologijo? Kateri ukrepi bi morali imeti prednost?
Naslovna slika: Ali Shah Lakhani (Unsplash).
Povezane vsebine